| ■ Zaurus持って、コミケに行こう! ■ |  |
|
コミケを戦い抜くのに必要なものとして、コミケットカタログがあげられます。無論、他にもお金やら糧食、大き目のかばん、それから知力、体力、時の運なども必要ですが、広大な会場でお宝をゲットするためには、宝の地図であるカタログが重要なことは、わざわざ私に言われなくても周知のことでしょう。あらかじめしっかりとカタログチェックして、周回予定のサークルさんをリストアップし、MAPにおとして準備するはもちろんですが、準備や仕事の都合でチェックできなかったり、当日並んでいる時にチェックしようと思っている人も多いと思います。また、いざ会場で回り始めると、突然忘れていたサークルさんの名前を思い出したり、並んでいる時に欲しかった本の情報を小耳に挟んだりと、会場内でカタログを引っ張り出す必要が出てくる場合もあります。一応カタログが入場券代わりとなっていることもあり、とりあえずコミケ用の荷物の中には入れておきたいものですが、あの「人も殺せる厚さ」を見ると、躊躇するもの確か。できれば荷物はなるべく軽くして、購入する同人誌のためにスペースを空けたいものですね。1日分ずつ切って分冊にする方法もありますが、さほど小さくはなりません(本好きにとっては、カタログといえど、本を切るという行為は、非常に抵抗があります)。時は、すでに21世紀。カタログも電子化され、カタロムとして一般販売されています。これをノートパソコンに入れれば、持ち歩くことができますが、ノートパソコン自体カタログ並みの大きさがあり、会場内で使用するには難があります。ここはひとつ、PDAにカタログを入れて、クールに使いたいものです。 では、私がやっている方法を紹介しましょう。私が閲覧に使用しているPDAはSharpのZaurus SL-C700&SL-C860。小型軽量でパワフル、きれいな液晶画面は日光の下でもきちんと認識できるので、外で並んでいるときでもチェック可能です。OSとしてLinuxが採用されてるため、多くのソフトが精力的に開発、移植されています。Zaurusには「HancomSheet」というExcel似の表計算ソフトが附属しており、Excel形式に変換したカタログデータを読み込ませて使用することもできなくもないですが、起動が遅いうえ、1日分のデータを読みこむだけで数分かかってしまうため、とても実用にはなりません。そこでフリーの電子辞書ソフト「Zten」を使用することにしましょう。これは電子ブックデータEPWING形式のデータを扱うことができ、動作も速く、とても扱いやすいソフトです。私のZaurusには、電子辞書の検索用にすでにインストール済みです。それに、このEPWING形式のデータなら、機種、OSを問わず、対応したソフトがあれば使えるので、他のPDAでも使えるはずです。なお、サークルカットをEPWING形式のデータに含ませることもできますが、作業が大変な上、時間も(技術も)ありませんので割愛しています。ちなみに、私は縮小した画像をそのままZaurusに入れ、イメージノートでチェックしています。
それでは、順を追って説明してみましょう。なお、この記述はコミックマーケット65のCD-ROMを元にしたものなので、その後データ形式等が変更になっている可能性があります。適宜読み替えて、工夫してみてください。 まず、必要なものは、次の通り。
作業の手順は次のような工程で行います。
コミケットカタログのCD-ROM版には、テキスト形式になったデータが収められています。これを、EBStudioで変換できる形式に作り直します。まず、EBStudioのヘルプを読むと、変換できる形式がいろいろと書かれています。この中でカタログの検索に向いており、作成もやりやすそうなHTML形式を作ることにします。HTML形式の中でも、複数の検索語を<Key>という特別なタグで指定することができる書式にあわせて、カタログデータを構成しなおすことにします。 カタログのデータは、CD-ROMのCDATAというフォルダに入っています。DOCUMENTというフォルダの中のDATA.TXTというファイルにデータの内容が書かれてますので、よく読んでどのような順番でデータが格納されているかを把握しておきます。それでは、読み込ませて見ましょう。 Excelを起動し、ファイルを開くを選択します。「ファイルの種類」をテキストファイルに変え、必要なデータを選択します。カタログのデータは1日ごとにわかれており、C65ROMx.TXT(xは1〜3の何日目かをあらわしてる)という名前になっていますので、これを選びます。ウィザードが立ち上がりますので、「カンマやタブなどの区切り文字によってフィールドごとに区切られたデータ」にチェックを入れ、完了をクリックすれば後は自動でやってくれます。1日のサークル数が1万件を越えていますので、それなりに時間がかかるかもしれません。操作やデータの変換に不安がある場合は、10件ほど抜き出して、それを変換して表示等のテストをして、良ければ本番を行うという方法をとると良いでしょう。この後、データを作成する際に、かなり時間がかかりますので、やり直しは大変ですから。
きちんと変換できているのを確認したら、まずデータの整理を行います。最初に余分なデータを消します。配置図用の座標やサークルカットのインデックス、サークルのURL、メールアドレスなどは必要ありませんので、その列を選択して削除します。私の場合、1日ごとに別のデータにしますので、参加曜日も消します。なお、後でサークルカットを確認するため、ページ番号は残しておきました。 次に、データの並べ替えを行います。データは、見出し語と説明分、そしてその間に検索用のキーが並びます。見出し語はサークル名と読み仮名。説明文は、それ以外。そして、検索用のキーは「配置地区」「配置コード」「ジャンル」「執筆者名」を指定します。 そして、下準備が必要なデータがあります。カタログデータ内では、ジャンルはコードであらわされています。いちいちジャンルコードを憶えてはいられませんので、コードをジャンル名に変換します。まず、ジャンルコードとジャンル名の対照表を作ります。CDATAの中のC65DEF.TXTというファイルにジャンルコードとジャンル名の対照リストがありますので、これをテキストエディタで開き、必要な部分をコピーし、別のテキストファイルにします。これをExcelで読み込み、コード順に並べ替えます。これをカタログデータから参照して、ジャンルコードからジャンル名を呼び出します。関数は、「VLOOKUP()」(範囲等は、ご自分の環境に合わせてください)を使うとよいでしょう。 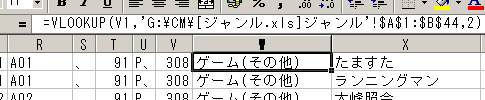 次に、配置コードを調整します。配置コードの数字部分は、1〜99(そこまではありませんが)の範囲で標記されています。この中から「5」を検索しようとすると「5」の他に「50〜59」も引掛ってしまいます。そこで、1〜9までの数字を「01〜09」に直します。ついでに、ブロック名のも全角に直しておきましょう。関数は「JIS()」と「TEXT()」を使ってみました。 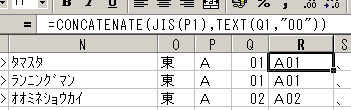 さて、ここで検索に使うソフトの挙動を確認しておきます。いろいろな条件のデータをテストして見たところ、ソフトによっては、読み仮名は半角カタカナではうまく検索できないモノがある(濁点が読めないようです)、先頭のアルファベットが小文字の場合は検索に引掛らない、などの問題があるものもあるようです。そこで、読み仮名は全角カタカナに、アルファベットのタイトルは、全角大文字に直してkeyに追加しておきます。Excelだと、「JIS()」と「UPPER()」の関数を使うとよいでしょう。 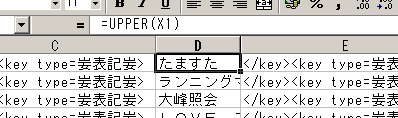 続いてHTML化のためのタグを追加します。この作業が今回の肝です。見出し語は<dt>というタグ、キーは<key>というタグ、説明文は<dd>というタグに挟まれています。これを追加するために、各データの前後に列を挿入します。 タグをつける際にちょっと工夫が要ります。このデータはテキスト化するためcsv形式で出力します。そのため、各データの区切りには「,(コンマ)」が入ります。これは必要ないので、出力前に一つにまとめるか、後にエディタの置換機能で消します。置換機能で消す場合には、区切りには「,(コンマ)」以外、たとえば「、(句点)」などを使用します。データ内に「,」が存在すると、そのセルはテキストとして扱うためか、「"」で囲って出力されてしまうので、使わない方が作業が楽です。 また、タグのパラメーターなどに「"(ダブルクォーテーション)」で囲む必要がありますが、Excelでは、csvで出力するとなぜかさらに「"」で囲んでしまい、余計なデータが追加されてしまいます。[例:"<key type="""標記""">"]そこで、あらかじめ「"」を別の文字で代用し、後で置換することにします。ここでは、「妛」を使ってみましょう(笑)。 それでは、タグを挿入していきましょう。見出し語の部分には、「<dt>」と「</dt>」で挟みます。検索語は「<key type=妛標記妛>」(本当は、<key type="標記">)と「</key>」、説明文は「<dd>」「</dd>」です。keyのパラメーターは「"」で挟む必要がありますが、先の理由により変わりに「妛」を使います。 それから、ちょっと知恵を使いましょう。検索語と見出し語は区別されないため、例えば配置コードの「A」を抜き出そうとしても、「A300愛好会」なんてサークル名も一緒に出てしまいます。そこで検索語の頭に識別用の記号をつけて、それだけ抜き出せるようにします。この例では、配置館は「!」配置コードは「#」ジャンルは「$」執筆者名は「%」を使います。いずれも数字キー部分にありますので、簡単に入力できますね。具体例としては、配置館の前のタグは「<key type=妛標記妛>!」(最終的には「<key type="標記">!」)となります。同様にして、すべてのタグをいれます。 最後に、「CONCATENATE()」関数で、必要なデータだけを一つに繋いじゃいましょう。一つにまとめられたら、CSV形式で保存したときに、余分な「,」が入らなくなります。問題なくまとめられたなら、追加した部分を、全部の行にコピーします。 
一度別名で保存しておきましょう。出力で必要なのは、最後の列だけですので、この列をコピーし、新しいワークシートに「形式を選んで張り付け」→「値」を選んで、文字列として張り付けます。そして、CSV形式で保存します。
できあがったCSVデータをテキストエディタで開きます。まず、余分に追加されている「,」があれば。エディタの置換機能で「,」を「」(何も指定しない)で置換して消します。件数が多いので、結構時間がかかる場合があります(エディタの性能による)。気長に待ちましょう。 次に、あらかじめ「妛」で代用していた引用符を「"」に置き換えます。これで、データのコアの部分ができました。
最終的にはまともなHTMLデータにするため、最初と最後に必要な<html>や、<head>、<body>などを追加します。これを保存し、ファイル名の拡張子も「htm」または「html」に直しておきます。
上記の作業を繰り返し、3日分のHTMLデータができあがったら、EBStudioを使って、EPWINGデータへと変換します。説明やヘルプをよく読み、3日分のデータを一つのEPWINGデータに変換できれば、おしまいです。今回のデータでは、2日目のデータ変換中に1個所エラーが出ました。補足説明中に「> <」を使っている部分があったため、タグと誤認識したようです。それぞれ「&gt; &lt;」(半角)に直して置くと、きちんと変換できます。 また、データを圧縮するソフトもありますので、うまく行くようでしたら使って見るのもよいでしょう。 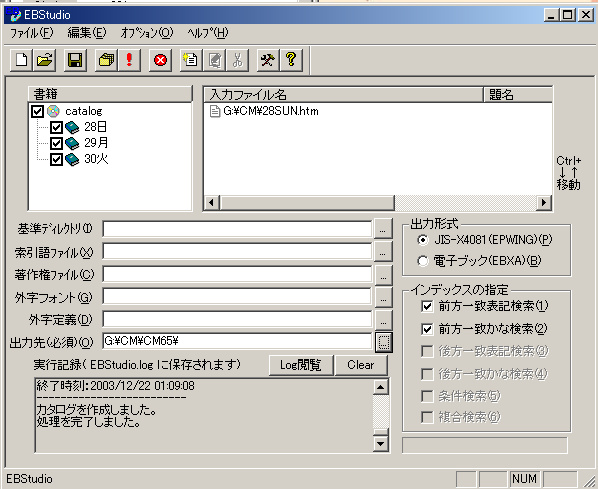 できあがったら、お手持ちの検索ソフトを使って、テストして見ましょう。サークル名はそのままでよいですが、配置コードなどで検索する場合は、先程追加した識別用の記号を追加して検索します。例えば、配置コードの「A-5」を検索したい場合は、「#A05」と入力します。検索結果のデータの並びは、この例では「サークル名」「読み仮名」「配置コード」「サークルカット掲載ページ」「ジャンル」「執筆者名」「発行誌名」「補足」となっています。うまく行きましたか?それでは、愉しんできてください。 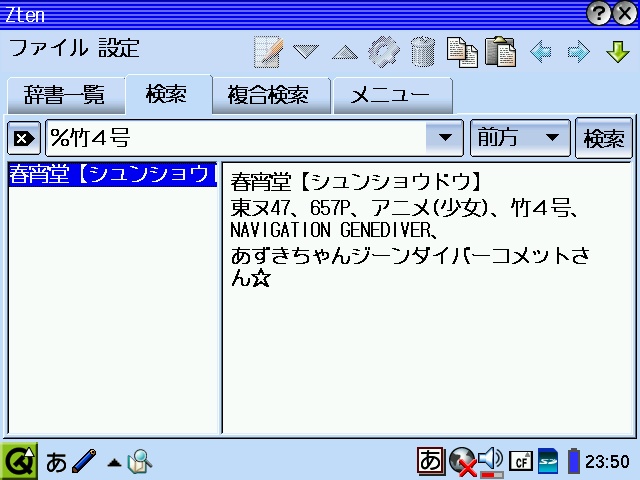
| ||||||||
| [竹4号(2003/DEC/23)] | ||||||||
| つづく・・・ |
| このページは、転載可です。特に許可はいりませんが、各ソフトの製作者やメーカーに迷惑のかからないようにしてください。また、ソフトのバージョンの変更により扱い方が変わる事がありますので、将来まで保証するものではありません。[竹4号] |
| ○メールは、こちらへ→ take4@zc.wakwak.com | [掲載物の転載について] (c)1997-2004 春宵堂/竹4号 All right reserved |