CloneCDは普通の方法では文字化けしてしまって日本語化できないので、かなり特殊で強引なやり方をします。この手法を再現するにはプログラミングが必要になります。
CloneCD2.8.3.1は言語パッケージを追加することで多くの言語に対応できるようになっています。"CloneCD.j"というファイルに適当な文字列リソースを入れてやって、レジストリの設定を少し変えれば日本語化することはできます。しかし、フォントが日本語フォントではないために文字化けしてしまい、使い物になりません。そこで、CloneCD自体を少し書き換えてフォントを日本語フォントに変更することになりますが、CloneCDの実行ファイルは内部構造がわからない上にバイナリエディタなどで書き換えるとエラーメッセージが出て実行できなくなってしまいます。「CloneCD勝手に日本語化」では書き換えの検出動作を無効にし、フォントを強引に日本語フォントに入れ替えるということを行います。
CloneCD.exeは起動時に自分自身の内容をチェックします。起動してかなり早い時期にCreateFileを呼び出してCloneCD.exeのファイルハンドルを取得し、CreateFileMappingでマップして内容をチェックするようです。チェックの結果自分自身の内容が変更されているとその旨のエラーメッセージを表示して終了してしまいます。
| CloneCD.exe | − | CloneCD.exeのファイルハンドルが欲しい | → | kernel32.dll |
| ← | CloneCD.exeのファイルハンドル | − |
そこでCloneCD.exe内のkernel32.dllに対する呼び出しをCloneCD.jに対する呼び出しに書き換えます。CloneCD.jにはCloneCDが使うkernel32.dll内の関数がすべてエクスポートしてあります。そしてCreateFileの動作を少し変更します。CreateFileはCloneCD.exeのファイルハンドルを要求されたときに、代わりにCloneCD.oldのファイルハンドルを返すようにします。
| CloneCD.exe | − | CloneCD.exeのファイルハンドルが欲しい | → | CloneCD.j | − | CloneCD.oldのファイルハンドルが欲しい | → | kernel32.dll |
| ← | CloneCD.oldのファイルハンドル | − | ← | CloneCD.oldのファイルハンドル | ← |
このようにして、CloneCD.oldの内容さえ変更しなければ、CloneCD.exeの内容をいくら書き換えてもCloneCDはエラーを出さなくなります。
基本的には上と同じ事です。user32.dll内のCallWindowProcとDefWindowProcでWM_SETFONTメッセージが送られたときに、設定フォントを日本語のフォントにすり替えます。
| CloneCD | − | フォントを"MS Sans Serif"に設定せよ | → | user32.dll |
| ← | 「正しく設定されましたよ」 | − |
これを次のようにします。
| CloneCD | − | フォントを"MS Sans Serif"に設定せよ | → | CloneCD.j | − | フォントを"MS UI Gothic"に設定せよ | → | user32.dll |
| ← | 「正しく設定されましたよ」 | − | ← | 「正しく設定されましたよ」 | − |
以上が基本的な仕組みです。ここからもう一工夫して、CloneCD.jができます。
CD-ROMに記録されるデータはセクタに分けて記録されます。各セクタには番号がふってあり、番号順に並べて記録されます。各セクタには2048バイトのデータが入り、データを読むときはセクタの番号を指定して読み込むことで目的のデータを取り出します。たとえば9つのセクタが次のように並んでいると仮定します。

これはごく普通のCD-ROMです。
ここで少しルール違反をして4から6のセクタを2回書いたとします。

4から6のデータが2重に記録されているのでこの部分が二重セクタと呼ばれているようです。
番号で書くのは面倒なので英字で区別しておきます。

ここでBとB2に同じデータを書いておいてもあまり意味がありませんが、違うデータを書いておけば興味深い結果を得られます。
前から順にデータを読み込んでいく場合、AとBは普通に読み込めます。でもBの終わりに達したとき、次にCが来るはずなのにB2が来てしまいます。ここでCD-ROMドライブが物理的なエラーでトラッキングを失敗したと判断すれば、「CはBの後に来るはず」と考えるのでB2を読み飛ばしてCを読み込むはずです。

結果としてABCが読み込まれす。
今度は逆に後ろからデータを読み込んでいくとします。Cの次にはB2が読み込まれます。その次にAをリクエストするのですが、そこにはBがあるのでCD-ROMドライブはシークに失敗したと判断してピックアップを少し前に移動させ、Aを読み込みます。

結果としてAB2Cが読み込まれます。
このようにいったん後ろのセクタを読み込んでからBを読み込もうとした場合だけB2が得られます。CD-ROMをコピーするソフトウェアは前から順番に読み込むだけなのでB2を読み込むことはなく、その部分がコピーされません。その結果、二重セクタはコピーを防止するプロテクトとして機能します。
このプロテクトは正しく機能する場合もありますが、しない場合もあります。問題はBの後にB2が来たとき、CD-ROMドライブがどのような挙動をするかという点にあります。B2を読み込んだときエラーチェックは全て正常で、単にセクタ番号だけが間違っているという状態になります。このとき一部のドライブはセクタ番号を無視してB2のデータをCのデータとして返します。結果としてABCとなるはずのところをABB2と読み込んでしまいます。
これを防止するためにはBとB2の境目に少し細工をします。そこにエラーセクタ(e)を入れておいてやるとどんなドライブもエラーを認識するので、Cを検索する体制に入ります。

ここではA、B、B2、Cの長さはそれぞれ3セクタということにしていますが、後ろから読むときのシークの精度がどのぐらいかわからないので、実際にはもっと長いほうが良いでしょう。5MB分の長さがあれば十分なようです。
このように書いたCD-ROMは前から読めば確実にABC、後ろから読めばAB2Cという結果になります。いろんなドライブでチェックしていますが、誤動作するものに遭遇したことはありません。
二重セクタはプロテクトとしてそれなりの性能を発揮するようですが、二重セクタの存在を知っている人には簡単にコピーされてしまいます。まず普通にイメージを作成し、次にCD-ROM全体を後ろから順番に読み込みながら先に作成したイメージと比較すれば二重セクタの位置や大きさ、内容などが全てわかってしまうからです。
セクタを三重にすることでそれを回避することができます。下記のようなCD-ROMがあったとします。

これは前から順に読めばABCDとなります。そして後ろから読むとDCBAとなるので一見セクタが多重になっているようには見えません。ACBの順で読み込んだ場合だけB2が現れ、ACB2となります。
幻のプロテクト2004/03/23版はこの方式です。
多重セクタを含むCD-ROMを前から順に読み込んでいくと、途中が読み飛ばされてしまうわけですが、どこが読み飛ばされたかを知ることができればその部分を後ろから前へ読み込んでいくことで隠されたセクタの内容を読み込めます。
セクタの読み込みにかかる時間を計ることでこれを知ることができます。セクタを順に読み込んでいるときは前のセクタの読み込みから次のセクタの読み込みまでの時間はCD-ROMが回転するのにかかる時間です。一方、読み飛ばしが発生した場合はこれがシークにかかる時間になります。シークにかかる時間は回転にかかる時間に比べて極端に長いのでこれを検出できます。次のグラフはそれを実際に計測したものです。読み込みに使ったドライブは東芝SD-R5002です。
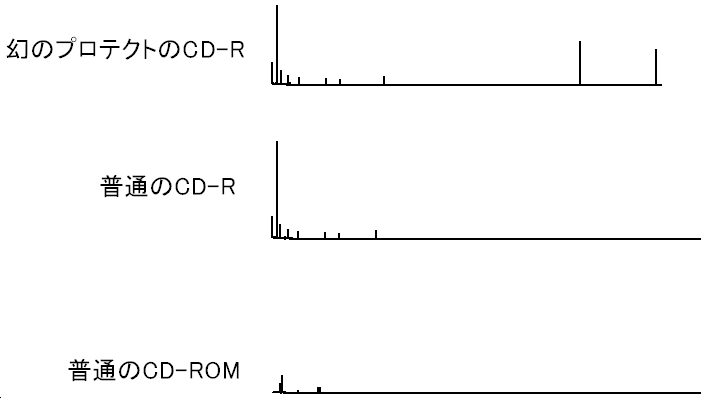
| CD-Rの書き込みドライブ | TEAC CD-W540E |
| 書き込み速度 | 最大 |
| 読み込みドライブ | TOSHIBA SD-R5002 |
| プロテクト | 幻のプロテクト2004/03/23版のサンプル |
縦の線はその部分で読み込みに時間がかかっていることをあらわします。左側がCD-ROMの前の方で右が後ろの方です。プロテクトの読み込み結果を見ると右のほうに二箇所、怪しげな線があります。この線の間がCの部分で、ここに多重セクタがあるとわかってしまいます。
トップページ http://park14.wakwak.com/~natsume/ 連絡先 master@chiyoclone.net PGP PUBLIC KEY